Getting started#
Colab Quickstart#
Check our classification models notebook and regression models notebook to see samples of sklearn_nominal models in action with simple datasets.
Installing sklearn_nominal#
sklearn_nominal is provided as a pip package. To install simply use:
pip install sklearn_nominal
Or if using uv:
uv add sklearn_nominal
Installing sklearn_nominal with export support for Trees#
Install using sklearn_nominal[export] to include support for exporting trees as png/pdf/svg.
WARNING: You need a working graphviz installation with headers in your system for export support. In ubuntu, use sudo apt install libgraphviz-dev to install the headers. This is a requirement of the pygraphviz and graphviz packages.
Fitting and evaluating a nominal model#
The process is the same as with any other scikit-learn model:
"""
============================
Train a TreeClassifier
============================
Train and evaluate a TreeClassifier on golf weather data
"""
import pandas as pd
from sklearn.metrics import accuracy_score
from sklearn_nominal import TreeClassifier
def read_classification_dataset(url: str):
df = pd.read_csv(url)
x = df.iloc[:, :-1]
y = df.iloc[:, -1]
return x, y, y.unique()
dataset_name = "golf_classification"
url_base = (
"https://raw.githubusercontent.com/facundoq/facundoq.github.io/refs/heads/master/"
)
url = url_base + "datasets/classification/golf_classification_numeric.csv"
x, y, class_names = read_classification_dataset(url)
# custom hiperparameters
model = TreeClassifier(
criterion="entropy", max_depth=4, min_samples_leaf=1, min_error_decrease=1e-16
)
# Fit and evaluate on training data
model.fit(x, y)
y_pred = model.predict(x)
print(f"Dataset {dataset_name:40} accuracy: {accuracy_score(y, y_pred) * 100:.2f}%")
# Print tree
print(model.pretty_print(class_names=class_names))
# Export tree as png
model.export_image("examples/tree.png", title=f"{model}", class_names=class_names)
In this case, we can inspect the tree that uses the nominal attributes directly afterwards:
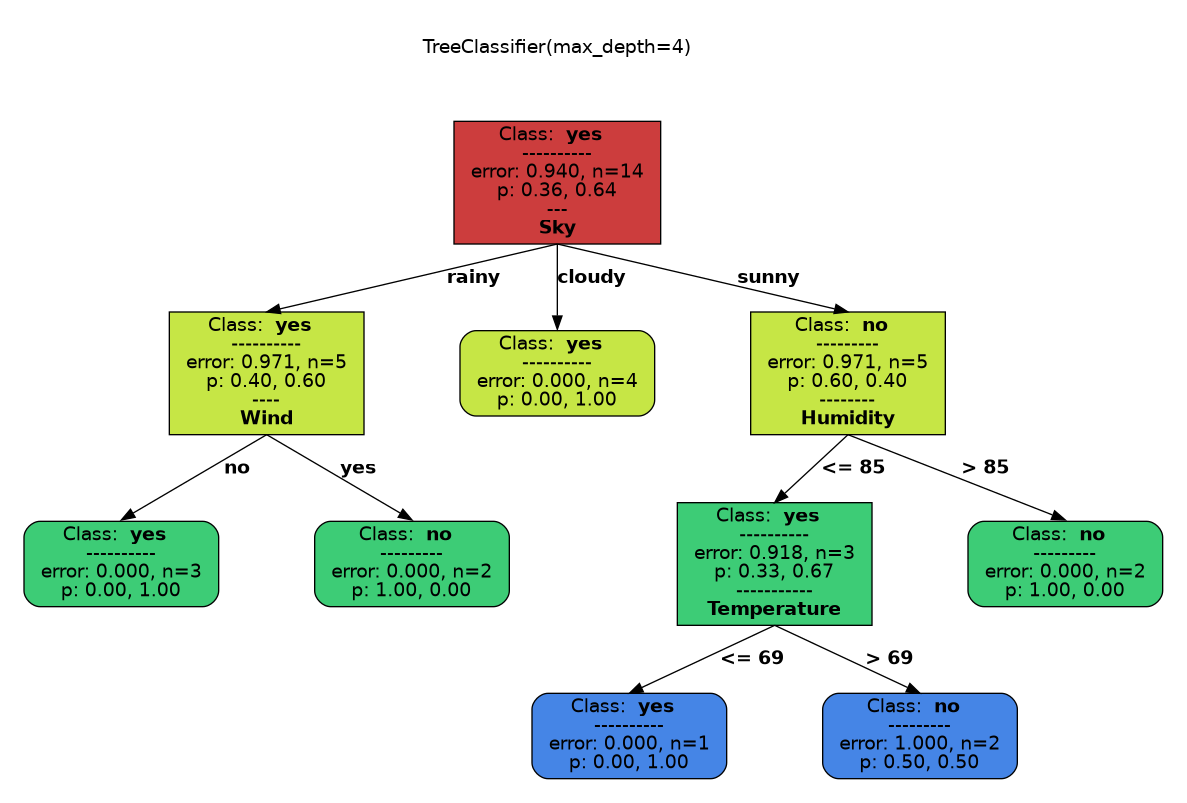
Tree generated after training on the Golf dataset.#
Comparing nominal classifiers#
We can compare the classifiers in terms of their accuracy for the same task.
We can also pretty_print each to visualize their differences.
"""
============================
Nominal classifiers comparison
============================
Compare scikit compatible classifiers available in sklearn_nominal
"""
import pandas as pd
from sklearn.metrics import accuracy_score
from sklearn_nominal import (
CN2Classifier,
NaiveBayesClassifier,
OneRClassifier,
PRISMClassifier,
TreeClassifier,
ZeroRClassifier,
)
def read_classification_dataset(url: str):
df = pd.read_csv(url)
x = df.iloc[:, :-1]
y = df.iloc[:, -1]
return x, y, y.unique()
dataset_name = "golf_classification"
url_base = (
"https://raw.githubusercontent.com/facundoq/facundoq.github.io/refs/heads/master/"
)
url = url_base + "datasets/classification/golf_classification_numeric.csv"
x, y, class_names = read_classification_dataset(url)
models = [
TreeClassifier(),
TreeClassifier(criterion="gini"),
TreeClassifier(criterion="gain_ratio"),
PRISMClassifier(min_rule_support=1),
CN2Classifier(min_rule_support=1),
OneRClassifier(),
ZeroRClassifier(),
NaiveBayesClassifier(),
]
results = []
for model in models:
model.fit(x, y)
y_pred = model.predict(x)
score = accuracy_score(y, y_pred)
print("===" * 20)
print(f"Model {model}")
print(model.pretty_print(class_names))
print("---" * 20)
print(f"Accuracy: {score:.3f}")
print("===" * 20)
print()
result = {"model": str(model), "accuracy": score, "complexity": model.complexity()}
results.append(result)
results_df = pd.DataFrame.from_records(results)
results_df.to_csv("doc/classifier_comparison.csv", float_format="%4g")
print(results_df.to_markdown())
The results can be compared in this table:
model |
accuracy |
complexity |
|
|---|---|---|---|
0 |
TreeClassifier() |
1 |
7 |
1 |
TreeClassifier(criterion=’gini’) |
1 |
7 |
2 |
TreeClassifier(criterion=’gain_ratio’) |
1 |
7 |
3 |
PRISMClassifier(min_rule_support=1) |
1 |
7 |
4 |
CN2Classifier(min_rule_support=1) |
1 |
5 |
5 |
OneRClassifier() |
0.714286 |
4 |
6 |
ZeroRClassifier() |
0.642857 |
1 |
7 |
NaiveBayesClassifier() |
0.928571 |
3 |
Controlling Attribute Penalization#
When working with nominal attributes, some features might have many unique values (high cardinality), such as “ID” or “Name”. These features can lead to overfitting because they can perfectly partition the training data without providing real predictive power.
The gain_ratio criterion addresses this by penalizing attributes based on their intrinsic information (the entropy of the split itself). You can control the strength of this penalization using the attribute_penalization_importance parameter.
attribute_penalization_importance = 0: Equivalent to standard Information Gain (Entropy).attribute_penalization_importance > 0: Increases the penalty for multi-valued attributes.
The following example demonstrates how different importance values affect the tree structure on the alsol.csv dataset, which contains high-cardinality features:
import pandas as pd
from sklearn_nominal import TreeClassifier
import os
# Load the dataset
# Using absolute path for the example to work in the dev environment
dataset_path = os.path.abspath(os.path.join(os.path.dirname(__file__), "../datasets/classification/alsol.csv"))
df = pd.read_csv(dataset_path)
# Features and target
X = df.drop(columns=["Quemado"])
y = df["Quemado"]
print("Dataset features:")
print(X.head())
print("\nUnique values per feature:")
print(X.nunique())
# 1. No penalization (importance = 0.0)
# This favors high-cardinality attributes like 'id', leading to overfitting
model_none = TreeClassifier(criterion="gain_ratio", attribute_penalization_importance=0.0, min_error_decrease=0)
model_none.fit(X, y)
print("\n--- Tree with Importance = 0.0 (Regular Entropy: Overfitted to 'id') ---")
print(model_none.pretty_print())
# 2. Balanced penalization (importance = 0.3)
# This penalizes 'id' enough to favor more generalizable features like 'Protector'
model_std = TreeClassifier(
criterion="gain_ratio",
attribute_penalization_importance=0.3,
min_error_decrease=0,
)
model_std.fit(X, y)
print("\n--- Tree with Importance = 0.3 (Balanced: Uses 'Protector' and 'Pelo') ---")
print(model_std.pretty_print())
# 3. Standard penalization (importance = 1.0)
# Note: At higher importance, the penalization can be so strong that
# it discourages any split, resulting in a single leaf (root-only tree).
model_high = TreeClassifier(
criterion="gain_ratio",
attribute_penalization_importance=1.0,
min_error_decrease=0,
)
model_high.fit(X, y)
print("\n--- Tree with Importance = 1.0 (Strongly Regularized: Root only) ---")
print(model_high.pretty_print())